scala编程读书笔记
• 从技术层面上来说,scala是一种把面向对象和函数式编程理念加入静态类型语言中的混合体。面向对象和函数式是两个不同层次的概念,它们并不是对立的,与面向对象对立的是面向过程,与函数式对立的是过程式。之所以要强调结合二者,是因为当前的编程语言在这方面做的不够好。写软件无非是两点:搭架子和添功能,所谓搭架子就是模块化,把软件拆成一个个可复用的独立模块,是软件架构的东西。而所谓添功能,就是添逻辑写代码了。面向对象是一种在工程实践中总结出来的工程设计模式,它的动机很简单:绝大多数程序都需要某种结构。最直接的方法就是把数据和操作放进某种形式的容器中。面向对象思想的伟大之处是把这种容器通用化,能够保存数据和操作,并能将这种容器保存在其它容器中,或做为参数进行传递,这种容器被称为对象。这种模式可以让最简单的对象与完整的计算机有同样的架构原则:用形式化的接口绑定数据和操作。使得构造小程序和构造大程序都可以应用同样的技术。也就是说,面向对象主要是在软件架构和模块化方面给我们带来了很大便利,是个搭架子的好帮手。面向对象有很多实现方式,最常见的就是java这种“类”的方式,另外还有javascript那种用原型的方式,还有函数式语言也能够通过高阶函数的特性实现对象的模拟。而函数式是一种编程范式,是有具体的理论依据的,过程式的理论依据是图灵机,而函数式语言的理论依据是Lambda演算。命令式编程是面向计算机硬件的抽象,有变量(对应着存储单元),赋值语句(获取,存储指令),表达式(内存引用和算术运算)和控制语句(跳转指令),一句话,命令式程序就是一个冯诺依曼机的指令序列。而函数式编程是面向数学(Lambda演算 )的抽象,将计算描述为一种表达式求值,一句话,函数式程序就是一个表达式。函数式语言之前一直不怎么流行,有一个很重要的原因是效率,现代计算机的架构:冯诺依曼体系是以图灵机为原型构建的,所以命令式语言更接近底层,函数式语言要想获得同样的效率,需要强大的编译器环境去做优化,做为语言使用者的普通程序员无法左右底层原生的东西。但编译器优化只是个时间的问题,并不阻碍人们对函数式编程精华的喜爱:写代码太爽了!一切都是表达式,非常统一;没有副作用,非常放心……因此,scala强调面向对象和函数式的结合,是出于对模块层次和代码层次两方面的自信,用面向对象构造模块,用函数式编写代码。另外讲到静态语言和动态语言,在写代码上各有优缺点,静态语言较严谨,比如有静态检查,对于一些语法拼写等简单错误,用不着运行,ide会直接报错。而动态语言写起来比较爽快,语法限制少,比如变量没有类型,都是var 定义,不用记int string什么的前缀。scala最好,即严谨又爽快,编译器强大!
• scala语言的名称来自于“可扩展的语言”。之所以这样命名,是因为它被设计成可以随着使用者的需求而扩展。从编写脚本到构建大型系统,全行,看心情。scala的几种运行方法如下:

• 和java这种包含基本类型和静态方法的伪面向对象不同,scala的面向对象是纯面向对象,一切值都是对象,一切操作都是对象方法的调用。123是对象,函数和方法(可以简单的认为函数和方法没区别,想复杂了也没用,因为写法和用法是一样的)也是对象;+ -这些在其它语言中被称为操作符的东西,在scala中都是方法,是的,scala没有操作符,它没有方法名必须以字母开头的限制,非常统一。因此,当我们设计一个新的类型时,可以给它添加这种以操作符命名的方法,这样就会让使用者产生在调用语言原生api的错觉和安全感。scala中也有if for等原生控制结构,但都进行了改造,使它们有了返回值,变成了表达式(while这种没有经过改造的不建议使用)。scala又是一种函数式语言,直持高价函数(函数做参数,做返回值什么的,其实这很容易理解,因为函数是对象)等特点。函数式搭上内建控制结构,使得我们非常容易实现自己的控制结构,其实就是给包括控制结构的函数起别名。以上两点也是scala号称可扩展的原因之一,也是为什么面向对象和函数式的结合,使scala更有可扩展性。
• 函数式编程有两种指导理念。第一种理念是函数是头等值:它是对象,是值,跟123一样一样的,随便当参数值传,随便当返回值用,这大大增强了语言的表现力,令使用者感觉很爽。第二种理念是函数没有副作用,函数只是数学中的一个函数,把定义域映射成值域,它并不改变什么东西。这个理念给并发带来了一个新思路。并发涉及到服务提供者和服务使用者两方面,对服务使用者来说,并不十分关心使用哪个解决方案来处理并发,甚至不在乎是不是并发,我发出请求,你按时返回准确数据就行了,但对服务提供来说,不同的解决方法对服务质量和写代码的心情有很大影响。传统的并发解决方案是多线程,把程序中有碍性能的部分提出来,封装成多线程服务,当有对这个服务调用的事件发生时,服务会启动一个线程(新建或从线程池中取)专门为之服务,服务结束后根据结果调用相应的善后方法(如默默处理一些数据,比如记录调用者数据到DB,或者回调调用者提供的一个接口,或者把结果写入公共内存供其它线程访问等),即通知调用者。不同线程之间以及调用者和服务之间(其实也是不同线程)的交互的方式往往是增删改查公共内存数据,这就难免涉及到最烦人的同步互斥和锁的问题,严重影响质量与心情;还有一种解决方案是异步事件驱动(如nodejs天然支持,netty自己实现了这种方式)。异步事件驱动服务,它的调用流程是调用者抛事件,抛完去干自已的事就好了(异步),服务处理完毕后根据处理结果调用相应的回调方法来通知调用者。那这不是和多线程差不多吗?用多线程,我也可以调用想要的服务并提供回调接口,然后服务也可以回调我啊?对调用者来说是这样,刚才已经说过,任何解决方案,对调用者都差不多。但对服务提供者来说差别就大了,在提供了异步事件驱动的语言或工具中,提供了一个统一的事件处理器,对事件进行了抽象,定义好的事件注册到事件处理器中,就可以对外提供服务了,所以服务提供者的主要工作量,从多线程时的为每个事件类型都写一套为之服务的线程,事件发生后新建或获取线程为事件服务,服务结束后调用善后方法等繁琐重复的逻辑,升级为写事件类型的处理逻辑并注册事件,就完事儿了。而且这里还特别强调了,是异步事件驱动,强制使用回调的方式去和其它线程交互,很省心。如网络通信工具netty,它有一个线程专门接受网络连接,系统注册了连接成功,发送数据,连接断开等很多事件,当有调用者连接服务或发送数据时,这个专门的线程会将其封装成事件抛给事件驱动系统,服务提供者要做的是编写各种事件的处理方法并回调(发送那么多类型的数据,每个都是不同的事件吗?一般不是这样处理,而是都归为发送数据事件,再根据数据内容的不同,写不同的处理方法,又是一种事件驱动)。scala的并发:actor model就更绝了。它把服务抽象成一个个的actor,内部有一个消息队列,提供唯一的一种请求服务和回调的方式:发消息。用scala提供并发服务,只需将功能写在actor里面,调用者调用这个服务时,向这个actor发消息就行了。
• 用类写软件,用表达式写类。
• 定义函数时,参数类型必不可少;结果类型时要时不要:函数是递归时要,正常情况不要。
• 函数字面量的语法构成是:括号及命名参数列表,右箭头及函数体:(x: Int, y: Int) => x + y。一般参数类型可以省略,因为可以推断出来,如果只有一个参数且省略了类型,那括号也可以省了:args.foreach(arg => println(arg));如果函数字面量只有一行语句且只有一个指代参数,那么连这个参数都可以省略:args.foreach(println), 这被称为偏函数。
• scala中没有操作符,都是方法。1 + 2其实是调用对象1的+方法,参数是对象2:(1).+(2)。当方法只有一个参数时,可以省略.和括号。scala中一切都是对象,一切操作都是对对象方法的调用,没有特例。通过下标访问数组:array(1),其实是调用的array的apply方法:array.apply(1);通过下标更新数组值:array(1) = 2,其实是调用数组的update方法:array(1).update(1, 2)。而且这也试用于所有对象,任何object(……)的写法,都是调用apply方法,这也是数组对象的访问用(),不用[]的原因,也进一步显示了scala的统一性。()与apply和update方法的转换,是scala编译器的行为,我们可以在类中自己定义这两个方法。val array = Array(1, 2, 3)是调用Array伴生对象的不定长参数的apply方法,返回一个Array[Int]对象,起到一个工厂方法的作用。
• var/val修饰的是变量名,而不是变量指向的对象。当用val时:val temp = Array(1),修饰的是temp,而非1。这时temp是不可变的,不能重新被赋值:temp = Array(2)非法;但是Array(1)对象是可变的:temp(1) = 2合法。scala中的对象有可变和不可变之分,如Arrray是可变的,List是不可变的,对Arrray对象操作,改变的是对象自身,对List进行操作,会返回一个新的List,原List不变。
• scala中方法正常都是左操作,如:1 + 2是调用对象1的+方向,传入参数2。有一个例外:以:结尾的方向是右操作,如:List(1) ::: List(2)调用对象List(2) 的:::方向,传入参数List(1)。
• 函数式编程崇尚val(不可变变量:都不可变了,还叫变量干吗?不如叫句柄,用来指向和操作对象的句柄),不可变对象,无副作用的方法。
• 返回值类型为Unit的方法,执行的目的就是为它的副作用(能够改变方法之外的某些状态或执行I/O活动),这种方法的推荐书写格式是:去掉返回值类型和等号,即参数列表后直接花括号函数体。只要不写等号,默认认为返回值类型是Unit,所以要返回其它类型,一定要写等号,因为任何类型都能转成Unit。
• scala不能定义静态成员,代之的是单例对象:object。当单例对象和类同名且在同一源文件时,单例对象是类的伴生对象,类是单例对象的伴生类,二者可相互访问对方的私有成员。单例对象相当于静态工具类,所有字段方法都是静态的,因此这里说的相互访问是指伴生类可以直接访问伴生对象中所有成员,伴生对象通过new伴生类拿到其实例,可以访问这个实例的所有成员。不与类伴生的对象叫独立对象,一般用于写程序入口点(main方法),工具类什么的。
• scala可以引入(import)对象成员,只要引入对象.方法就可以使用这个方法而不用加对象.前缀了。scala默认引入了包java.lang,包scala及Predef对象的成员,println就是Predef成员的一个方法,所以可以直接调用println方法,不用Predef.println。
• scala中任何操作符都是方法,对象 + 对象 = 对象.+(对象);任何方法都是操作符:list.indexOf("o") = list indexOf "o",list.indexOf("o", 5) = list indexOf ("o", 5)(多参数时用括号括起来)。
• 大多数操作符(方法)都是中缀(对象 方法 对象)和后缀(对象 方法)操作符,后缀即是中缀没参数。因此,写一个方法,scala默认它是中缀和后缀。但如果我就是想写一个前缀的怎么办,如取负。写一个-方法,默认会调 对象.-,而不是 -对象。scala规定了四种操作符可以为前缀操作符:+,-,!,~。只要定义unary+这种方法,就可以这样使用了:+对象,即:对象.unary+ = +对象。但是unary_只对这四种操作符有用,其它操作符没有这种转化。
• 后缀操作符没有参数,没参数的方法可以省略()。对方法的写法和调法有一个约定:如果方法没有副作用,则不带();如果方法有副作用,则带()。
• scala中常量名的习惯写法是首字母大写,而不是全大写。下划线不常用在标识符中,因为它有很多其它用法,如和java中的一样,代表全部。任何字符放在反引号``中,都成为一个字面量标识符,如yield是scala关键字,所以不能直接Thread.yield()这样调用java方法,应该是Thread.`yield`()。
• scala中有符号字面量:’aaa,是scala.Symbol的实例。
• 字符串字面量有三引号写法,会保持引号内内容的原生态(回车什么的特殊字符也保持,不用转义)。有一个问题是,我们经常为了代码的对齐美观,加一些字格什么的,这也会被保持住,怎么去掉这些无用的空格呢?每行前面加管道符号|,最后调stripMargin方法。
• scala的内建控制结构仅有if while for try match和函数调用。这些控制结构都有返回值,其中while的返回值类型是Unit,和没有一样,太不函数式了,不建设使用。
• scala中 == 的执行顺序是:先比较左操作对象是否为null,当左操作数是null时就判断右操作对象是否为空,如果是返回true,不是则返回false;左操作数不是null则继续调用左操作对象的equals方法。
• scala中定义常量名的惯例与java不同,并不是全大写,而是首字母大写。变量名的定义一般不用下划线,因为下划线有其它意义,比如包引用时,代表全部,相当于java中的。
• scala中的Unit和java中的void并不相同,Unit类型有唯一值()。
• for表达式中的概念:生成器,过滤器,流间变量绑定。子句可以在小括号中,也可以在大括号中,在小括号中时,生成器,多个过滤器之间要加分号,大括号则不用加,所以一直用大括号就行了。
• throw有返回值Nothing,可以做任何类型的值,因此可以当作表达式的一部分,不用单独处理有异常的情况。scala中没有受检异常。
• try—finally可以产生值。finally子句的作用是做一些清理工作,不建议返回值(return),它计算产生的值将被抛弃。这里讲到返回值和产生值,返回值指的是显示return的值,scala认为代码块的最后一个语句产生的值为返回值,不用写return,这叫产生值。如果在finally子句中返回值,那么它将覆盖try和catch子句中所有返回或产生的值;如果在finally子句中产生值,那么它将被抛弃。因此,不要在finally子句中产生值和返回值,另外,干脆在scala中抛弃return多好。
• scala中没有continue和break,请用if和布尔变量分别替换这两种语句,或用递归替换循环。
• scala中变量作用域由花括号形成,与java不同的是,嵌套作用域内的内层可以定义与外层相同的变量名。
• 偏函数(PartialFunction)和偏应用函数(Partial Applied Function)。偏函数是数学中的概念,它并不是函数,而是和函数并列的一个概念。函数是把定义域上所有的值(全集)映射成值域上的值,称为全函数;而偏函数指的是,定义域中的有些值可能在值域中找不到映射,即只映射定义域的子集。scala中可以通过模式匹配来定义偏函数,如下例中只对大于1的定义的进行映射:
def p1:PartialFunction[Int, Int] = {
case x if x > 1 => 1
}
def p2 = (x:Int) => x match {
case x if x > 1 => 1
}
你可以在调用前使用一个isDefinedAt方法,来校验参数是否会得到处理。或者在调用时使用一个orElse方法,该方法接受另一个偏函数,用来定义当参数未被偏函数捕获时该怎么做。偏应用函数,也叫做部分应用函数,是缺少部分参数的函数,是一个逻辑上的概念。比如定义一个函数:def sum(a: Int, b: Int, c: Int) = a + b + c,我们可以通过部分应用,让这个函数产生一个偏函数:def p_sum = sum(1, _: Int, _: Int),把1这个值应用到了第一个参数,p_sum函数只传入两个参数就行了。为什么p_sum是sum产生的一个偏函数呢?因为psum只对参数a的定义域上的1进行了映射。
• 怎么又能在函数字面量里当某个参数的占位符,又在偏应用函数里指代某些或全部参数,书里还放在一块儿说,二者有什么关系吗?什么乱七八糟的。——二者没什么关系,唯一的关系就是都可以作为简写函数字面量的方式,它们是的两种不同用法。有很多用法,包括:
1. 函数字面量里的占位符:`List(1, 2, 3) filter {_ > 0}`。函数字面量有很多简写方式,如在可推断参数类型时,可去掉参数类型,只有一个参数且省略了类型,那括号也可以省了。占位符也是一种简写方式,当变量在函数字面里的函数体中只出现一次时,可以把函数字面量简化成一个表达式,用占位符代替参数:`List(1, 2, 3) filter {x => x > 0}` 和 `List(1, 2, 3) filter {_ > 0}`是一样的,也可以是多个参数,只要每个参数只出现一次就行:`List(1, 2, 3) reduceLeft {_ + _}`。这些例子里,参数都没有写类型,因为可以从List(1, 2, 3)中推断出来,所以可以不写,如果推荐不出来的话,不写不行,如 `val sum = _ + _ `,把函数字面量_ + _赋给了变量sum,会报错,因为不知道参数类型,所以必须 `val sum = (_: Int) + (_: Int)`,注意括号不能省,之前已说过省略类型才能省略括号;
2.偏应用函数:List(1, 2, 3) foreach {println _}。这里_不是某一个参数的占位符,而是全部参数的占位符。println _是偏应用函数,_是全部参数,也可以指某个参数,比如:def sum(a: Int, b: Int, c: Int) = a + b + c,def m = sum _,def s = sum(1, _: Int, 2)。sum _和sum(1, _: Int, 2)都是偏应用函数表达式,其中前者映射参数a b c的定义域全集,后者映射参数a = 1,c = 2,b全集。m和s分别指向一个由偏应用函数表达式产生的函数值对象。对m和s的调用:m(1, 2, 3) s(2)会转为调用值对象的apply方法。那为什么println _不是函数字面量占位符,而是偏应用函数表达式呢?不晓得。如果你正在写一个省略所有参数的偏函数表达式,如println _或sum _,正好某函数接受一个函数为参数,那就可以把这个表达式传进去,更简明的是,这种情况下,连_都可以省了:List(1, 2, 3).foreach(println)。
3. _还可以当通配符,和java中的*一样。
• 全偏应用函数(用_代替所有参数)的一个很重要的作用是把任意def变为函数值,下条笔记有说明。
• 当函数a的内部函数b被函数a外的一个变量引用的时候,就创建了一个闭包。如果函数b内引用了它的外部函数(函数a)的变量i,那么在函数a外使用这个函数b时(比如函数a返回函数b以供使用),函数b和i就被闭住了,即连代码带运行环境形成了一个整体(闭包):
def a(i: Int) = {
def b(x: Int) = {
i + x
}
b _ (上一条笔记)
}
或:
def a(i: Int) = (x: Int) => i + x
• scala支持可变长参数,语法是 def a(args: String)。可变长参数内部其实是一个数组,本例是Array[String],然而,要把数组传给它还不行,得用这种语法:a(array: _)。: *把数组转成可变长参数,这也是的另一种用法。
• scala中建议用递归代替while。while虽然很不函数式,但是一般认为while的效率更好一点。怎么取舍呢?——用尾递归,即在最后调用函数,这样编译器就会优化,没有性能开销了。但是scala编译器的优化是有限的,它仅能优化在最后调用自己的这种尾递归,其它的,比如间接调用自己什么的,不能优化。
• 柯里化怎么跟偏应用函数有点像呢?
• 函数的规格声明(函数是什么类型)是:(参数类型列表) => 返回值类型,即 (…) => Type。如以下代码:
def myAssert(check: () => Boolean) =
if(!check()){
println("OK ...")
throw new AssertionError
}
函数myAssert接受一个函数型参数,这个函数型参数为没有参数,返回值类型为Boolean。
调用这个函数: myAssert(() => 5 < 3)。要传入一个函数字面量:() => 5 < 3 。这样太麻烦了,要是能直接传入 5 < 3 多好啊,像这样:myAssert(5 < 3),直接传函数体。这也可以做到,利用scala传名参数的特性:函数类型的参数的参数列表为空时,可以省略()来定义:
def myAssert(check: => Boolean) =
if(!check){ // ()也可以去掉了
println("OK ...")
throw new AssertionError
}
myAssert(5 < 3)
有人说,这不多此一举吗,直接这样多好:
// 去掉了 => 映射符号
def myAssert(check: Boolean) =
if(!check){
println("OK ...")
throw new AssertionError
}
myAssert(5 < 3)
这两种方法是有区别的,一个是传名,一个是传值。传名的时候,用到才算,传值是先算出来:
// 传名参数的函数
val isValid = false
def byName(check: => Boolean) =
if(isValid && !check){
println("byName ...")
throw new AssertionError
}
// 常规的布尔变量函数
val isValid = false
def byBoolean(check: Boolean) =
if(isValid && !check){
println("byBoolean ...")
throw new AssertionError
}
scala> byBoolean( 1/0 == 0) // 报错
java.lang.ArithmeticException: / by zero
at .<init>(<console>:8)
at .<clinit>(<console>)
scala> byName( 1/0 == 0)
// 执行后没有任何输出因为用到才算,所以是在if(isValid && !check)中算,isValid就返回了,没算到。
!传名参数——去掉空参数括号。要想把传参改为传名,加一个 => (参数为普通对象)或去掉空参数括号(参数为无参的函数对象)就行了。
• 在传入一个参数时,可以用花括号代替小括号的机制,其目的是让客户程序员能写出包围在花括号内的函数字面量,让方法调用感觉更像控制抽象。利用柯里化,把多个参数的函数转成多单个参数的函数,最后一个参数就可以用花括号了。
• 无参数方法和空括号方法。当方法没有参数时,可以省略空括号,这种方法叫无参数方法。不管是无参数方法,还是空括号方法,调用的时候都可以省略括号(无参数方法必须不写括号)。scala建议:方法无副作用时,定义成无参数方法;有副作用时 定义成空括号方法。调用也是一样。scala类中的字段和方法是同一命名空间(所以字段和方法不能重名),所以无参数方法和字段在访问上没什么区别,无参数方法访问时要计算值,所以速度比字段慢,在新建类的对象时,字段要占空间,这点不如无参数方法。
• scala中类的成员(不考虑类,只考虑类中的成员:属性和方法)一共有三种访问修饰符:public(默认)、private和protected。
java有四种访问修改符:public、private、protected和package-private(默认)。
其中,public是scala默认的访问修饰符,package-private是java的默认访问修饰符。
scala没有package-private(包内可见)修饰符,但是可以给private和protected加包和对象权限。
java的protected修饰符为包内和子类可见,scala仅为子类可见,更为严格。
scala属性:
| 访问修饰符 | 最高可见范围 |
|---|---|
| public | 全体可见 |
| private | 本类及伴生对象内可见 |
| private[包名(e.g.,ustc.marin)] | 本类及伴生对象及ustc.marin包内可见 |
| private[对象引用名(e.g.,this)] | this对象可见(this.f行,that.x不行) |
| protected | 子类可见 |
| protected[包名(e.g.,ustc.marin)] | 子类及ustc.marin包内可见 |
| protected[对象引用名(e.g.,this)] | 同private[this] |
可见,加了包或对象权限的private和protected,可能扩大权限,也可以缩小权限。
scala运行在jvm上,它的编译结果也是class文件,用jd-gui反编译成java文件,可以看到:
public的属性会编译成private的属性和public的getter setter方法;
private的属性会编译成private的属性和private的getter setter方法;
private[this]的属性会编译成private的属性,没有方法;
private[包]、protected、protected[包]、protected[this]会编译成private的属性,public的方法 ——这个很奇怪,感觉对不上,protected的为什么会反编译成public的呢?这不乱了吗?其实不乱,scala是静态语言,它的运行时把.scala编译成.class文件在jvm上运行,把.scala编译成.class这个过程会做很多事情,这其中就包括检查访问权限,如果不符合scala标准,直接报错,到不了jvm运行。所以这里建议: 不要想反编译成java文件是什么样的,记住scala的规则就好了。
方法(函数也一样):
方法体: 总体上和属性一样。
方法参数: 方法的参数必须都是public(默认,不用写,写会报错) val的,没的挑。
a: Int, b: String = public val a: Int, public val b: String。
类参数:
- 带变量修饰符(val/var a: Int(带变量修饰符,一定带访问修饰符,因为public默认)、private val/var a: Int …): 和属性一样,生成私有字段,公有或私有getter setter方法。
- 不带变量修改符(类似方法参数的写法:a: Int, b: String ): 如果有其它方法(不包括构造方法。scala中直接写在类里,和属性方法并列的语句,会编译到构造方法里)使用了类参数字段,则生成私有字段;如果没有被使用,则连字段都不生成,getter setter方法更没有了。因为这种情况肯定不会生成getter setter方法。所以要想在其它类里访问不带访问修改符的类参数,得在被访问的类里另外定义属性=类参数或写getter setter方法。
• 要想成员和类不被重写,加final。
•
• ==方法和!==方法都是定义在Any类中的方法,因此所有对象都可以调用。这两个方法都是final的,不能被重写。其实这两个方面内部调用的是equals方法,重写equals方法就行了。
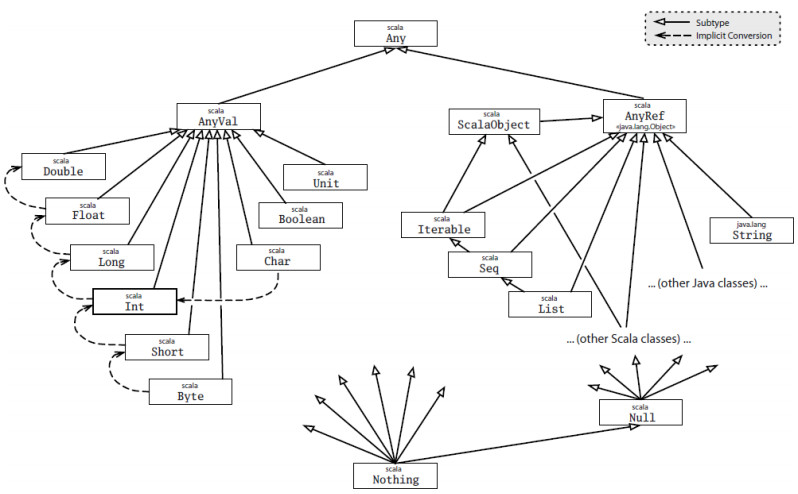
• AnyVal下的九个类型都是抽象且final的,所以不能new,只能通过字面量新建。Unit的唯一实例是()。
• Null是AnyRef的子类型,它的实例是null,可以被赋给AnyRef的类型,不可以被赋给RefVal下的值。Nothing是任何类型的子类型(包括Unit),根本没有实例。那有什么用呢?可以用它来标明不正常的终止。
• scala的类型是有根儿的,任何继承关系都能到最根儿的Any上。scala中可以继承一个超类和混入若干特质,根据这些超类和特质的继承关系和先后关系,构成一个线性化的序列。 线性化的先后关系是:由子到父(继承关系),由右到左(混入的先后关系)。当调用某类的某个方法时,会按照这个线性关系找,直到找到具体方法截止。特质有一种特殊的功能:它调用父类的方法是动态绑定的,直到它被混入到另一个特质或类中,根据线性化有了具体的方法定义时才工作,语法是super.方法。所以根据线性化找某方法时,如果找到的方法里调用了super.方法,那它就会给它后面的方法产生影响,形成可堆叠的改变。常规的做法是让特质继承某个类,这样,就只有这个类的子类可以混入这个特质了,特质中进行super调用时,会对混入它的子类产生可堆叠效果。
• import fruits.{Apple => A, Orange} 引入fruits包的Apple类和Orange类,并把Apple类重命名为A;import fruits.{Apple => A, _} 引入fruits包中所有的类,并把Apple类重命名为A;import fruits.{Apple => _, _} 引入fruits包中所有的类,排除 Apple,重命名为即是排除;`import p.等价与import p.{}`import p.n 等价于 import p.{n}。
• 样板类case做了三件事情:生成了与类名相同的工厂方法,不用new了;类参数都加了val,即生成了对应的字段;生成了toString hashCode equals方法,因为==调的就是equals,所以可以直接比较了。
• 模式匹配的语法是:选择器 match {备选项} 。 每个备选项都包含一个模式及一个到多个表达式,模式和表达式用 => 分开。模式匹配有很多种模式:类似于“1”、Nil这种常量模式匹配的值等于用==判断相等的常量。类似于e这种变量模式匹配所有的值(常量也可以有符号名,如Nil math.Pi等,怎么区分它是常量模式还是变量模式呢,scala有约定:小写字母是变量,其它是常量),注意:模式变量只允许地模式中出现一次,我想匹配Binop("+", x, x)怎么办,可以用模式守卫:Binop("+", x, y) if x == y => x + y 。通配模式 同样匹配所有值,也可以代替List中、函数中不在乎的参数,那和变量模式有什么区别呢,变量模式的变量可以绑定到模式上,表达式中可用,有的模式不方便用变量模式,或者变量模式中的变量满足不了表达式要用的变量,怎么办?可以显示分配变量:case Unop("abs", e @ Unop("abs", _)) => e,把Unop("abs", _)分配给变量e。构造器模式Unop(“-“, e)匹配所有类型为Unop并且第一个参数匹配”-“,第二个参数配置e(所有值)的值。序列模式 case List(0, _*) 匹配所有第一个元素为0的不定长List,case List(0, _, _) 匹配第一个元素为0的长度为3的List。元组模式 case (a, b, c) 匹配长度为3的元组。类型模式 用于判断类型,比较常用,case s: String => s.length,case m: Map[_, _] => m.size 分别匹配String和Map类型,注意由于类型擦除,类型模式不能配置Map等结构的范型,即只能匹配Map[_, _],不能匹配Map[Int, String],但是Array除外。
• 修饰符 sealed(封闭)的作用是:除了类定义所在的文件之外,不能再添加任何子类。这有效的防止了用户添加新的模式可选项,只能匹配定义好的那些类。
• 花括号内的样式序列,即备选项,其实是函数字面量,它是一个函数,函数的类型和模式对应:模式=>表达式:
val withDefault: Option[Int] => Int = {
case Some(x) => x
case None => 0
}
把花括号内的样式序列赋给变量withDefault,withDefault的类型是Option[Int] => Int。调用的方法是:withDefault(Some(10)) withDefault(None)。
• 列表是协变的,List[String] 是List[Object]bject的子类型。空列表List(),Nil的类型是List[Nothing],因为Nothing是任何类的字类型,所以空列表是任何列表的子类型。
• List的head和tail方法,分别返回列表第一个元素和其余元素,这两个方法只能作用于非空列表。
• 通过模式拆分列表,是比较推荐的方式。当知道长度时,使用:val List(a, b, c) = fruit ,长度为3,通过abc访问列表中的3个元素。当不知道长度时,使用:val a :: b :: rest = fruit,通过abc访问列表的前两个元素和其余元素,其中rest是列表类型。那么,这种模式是什么类型呢,好像和之前讲的模式类型都不一样,它是抽取器模式。
• List映射:map flatMap foreach方法。map的右操作元是一个函数,对List中所有元素调用这个函数,并返回结果List;flatMap的右操作元必须是返回值类型为List的函数,对List中每个元素调用这个函数,把生成的List组装成一个List返回;foreach的右操作元是过程(不是表达式,不返回结果),foreach不返回结果。
• List过滤:filter partition find takeWhile dropWhile span。其中filter返回列表中所有满足条件的元素组成的列表;partition返回由列表中满足条件的元素组成的列表和不满足条件的元素组成的列表组成的链表;find返回列表中第一个符合条件的元素的Some(x)或None;takeWhile返回列表从左到右满足条件的前缀列表;dropWhile移除列表从左到右满足条件的前缀,返回剩余列表;span是takeWhile和dropWhile的结合,返回两个列表组成的列表。
• List的论断:forall exists。其中forall判断列表中元素是否全满足条件;exists判断列表中是否包含指定元素。
• 列表折叠:/:和:\。(z /: List(a, b, c)) (op)op 等价于 op(op(op(z, a), b),b, c) ,(List(a, b, c) :\ z)(op) 等价于 op(a, op(b, op(c, z)))。
• scala的类型推断是基于流的,在m(args) 的方法调用中,类型推断器首先检查方法是否有已知类型,即方法调用者的类型,如果有,就把这个类型应用于函数体:"abc" sort (_ > _)通过调用者”abc”的类型推断为 "abc" sort ((x: Char, y: Char) => x > y)。当不能从调用者类型进行推断时,推断器进而会从第一个参数进行推断,这里有个问题:只有非函数值字面量才能推断出类型,所以在设计类库时,一定要把函数类型的参数放在参数列表的后面。如果从推断不出来怎么办?只能显示的指定参数类型了:"abc" sort ([Char]_ > _)。
• scala的集合:Seq(序列)——List(不可变,适合在头部快速添加删除,不适合操作尾部,不提索引访问任意元素, 和java中的list不一样,java中可get(索引)), Array(大小固定,可变,方便通过索引访问任意元素), ListBuffer(可变,头添加和尾添加时间复杂度都是常量,可toList转成List), ArrayBuffer(可变,可从头或尾添加元素), Quene(有可变和不可变两种), Stack(有可变和不可变两种);Set(集)——Set(有可变有不可变两种,不可变的空集:EmptySet), TreeSet(有可变和不可变两种,有序);Map(映射)——Map(有可变和不可变两种,不可变空映射:EmptyMap), TreeMap(有可变和不可变两种,有序)。想要使用同步的集和映射,可以混入SynchronizedSet和SynchronizedMap: val synchroSet = new mutable.HashSet[Int] with mutable.SynchronizedSet[Int],为什么都是可变的呢?因为不可变的本来就线程安全啊。不可变的集合类也有和可变的集合类一样的方法,比如 + 什么的,不可变集合类调用这些方法时,并不是改变的对象本身,而是返回的一个新的对象,集合类对以 = 结尾的方法,+= -= 这些,都会转化成 对象 = 对象 +。要显示的指定集合类保存哪种类型的元素,需要用泛型:Array[Any];要把列表中元素保存在TreeSet中,不能直接把List传给TreeSet的工厂方法,没这种接受List的工厂方法,应该先建一个适合类型的空TreeSet,再调用 ++ 方法:TreeSet[String]() + List("a")。
• 信息隐藏的解决方案有:私有构造器及工厂方法(类参数前加private,即主构造器不对外开放,然后另写公开的,没有类参数信息的构造器或工厂方法),私有类(类前加private私有化,做为内部类包在对象这中,对象提供工厂方法返回这个内部类)。
• 协变:trait Queue[+T],如果S是T的子类型,则Queue[S]是Queue[T]的子类型;逆变:trait Queue[-T],如果T是S的子类型,则Queue[T]是Queue[S]的子类型。java中数组是协变的,scala中不是。不允许使用+号注解的类型参数用做方法的参数类型,因为方法可能对这个参数进行与类型相关的操作,这样可能导致错误,但是可以加下界:类型参数为+T,方法参数类型不能为T,可以为U :> T,即T是下界,接受T的超类,返回值为U类型。下界为U <: T,即U必须是T的子类。
• 对相同的输入,总是返回相同的结果且没有副作用,就是函数式,其内部怎么实现的,有没有改变内部变量,不重要。scala中为了满足性能的需求,在很多api的实现上使用了var得不函数式的东西,但是外部访问不到。
• 类中成员除了属性和方法,还可以有类型成员:type S = String,用于给类型指定别名。
• scala中抽象不仅限与方法,类型、val、var都可以被抽象:
trait Abstract {
type T
def transform(x: T): T
val initial: T
var current: T
}
• 抽象的val成员,因为val是不可变的,所以必须由val具体化,不能由def具体化,因为def方法不能保证不可变,编译器直接不承认;而抽象方法,可以由val实现。
• 特质没有类参数。特质有一个特殊语法,那就是直接new,并把抽象val的具体值包在花括号里传过去:
trait RationTrait {
val a: Int
}
new RationTrait {
val a = 1
}
这会产生一个混入了RationTrait特质的匿名类。
这和直接new Ration(1)类(实现了抽象类)有什么区别呢?直接new类,参数是在类初始化之前传入的,而new特质传参数是匿名名构造出来之后传入的,所以如果构造过程中用到了这个参数 new类直接可用,new特质访问不到,如果构造过程中没用到这个参数,那效果没区别。可以通过两种办法解决这个问题:预初始化字段和懒加载val:new {val a = 1} with RationTrait, new后加花括号是预初始化字段;val前加lazy,是懒加载,会在用到时才初始化。
• 抽象类型挺有意思:type T。之前讲过类参数化的东西,可以细粒度的控制类及方法为哪些类型服务,当类中方法想规定服务类的范围时,可以定义一个抽象类型为某类型的下界,由子类实现:
class Food
abstract class Animal {
type SuitableFood <: Food
def eat(food: SuitableFood)
}
抽象类中定义了一个类型成员,必须是Food的子类,方法中用到了这个类型。
class Grass extends Food
class Cow extends Animal {
type SuitableFood = Grass
override def eat(food: Food) {}
}
这样,牛只能吃草了,吃不了别的Food。
val c = new Cow
c.eat(fish) // 报错。
c.SuitableFood 叫路径依赖类型。这与内部类挺像,但是scala中内部参得通过#访问:outer#inter。
• 隐式操作在哪里尝试:转换为期望类型、指定调用者的转换(定义 implicit def intToRational(x: Int) = new Rational(x, 1),调用 1 + new Rational(1, 2)时,1没有+(Rational)这个方法,会把1转成Rational(1, 1))、隐式参数(相当于默认值参数,挺麻烦)。转化方法为普通方法前加implicit,放到作用域内。
• ::是List的一个子类,不是List的方法,它的主构造器接受两个List型的参数,所以x :: xs 相当于调用::类的构造方法。
• 高阶函数和优点是简练,缺点是有的时候不易读,转成for表达式就易读多了。scala将带yield的for表达式转译成有返回值的高阶函数,如map等,没yield的转译成没返回值的高阶函数,如foreach等。所以二者可以相互转换。
• 之前讲的模式匹配中的构造器模式与样本类相关联,那不是样本类怎么办?不能用模式匹配了?可以用抽取器,类中定义unapply方法,返回可匹配的类型,如Option。调用模式匹配时,会调用这个方法把对象分解。
• *表示列表剩余元素:`List(1, *)`。
• 有三种情况使用implicit: 一是转换成预期的数据类型,二是转换selection的receiver,三是隐含参数。转换成预期的数据类型比如你有一个方法参数类型是IndexedSeq[Char],在你传入String时,编译器发现类型不匹配,就检查当前作用域是否有从String到IndexedSeq隐式转换。转换selection的receiver允许你适应某些方法调用,比如 “abc”.exist ,”abc”类型为String,本身没有定义exist方法,这时编辑器就检查当前作用域内String的隐式转换后的类型是否有exist方法,发现stringWrapper转换后成IndexedSeq类型后,可以有exist方法,这个和C# 静态扩展方法功能类似。隐含参数有点类似是缺省参数,如果在调用方法时没有提供某个参数,编译器会查找当前作用域是否有符合条件的implicit对象作为参数传入(有点类似dependency injection)。